重链剖分
\(2019.6.29\ update:\)给出了时间复杂度的证明,更新了\(L_AT^EX\)
先引入一个问题:
1 | 给定一颗有n个节点的树,给定根节点 |
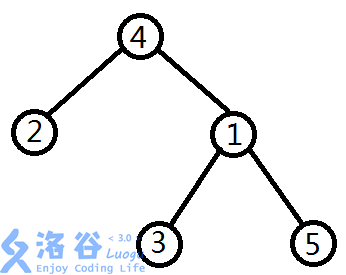
看到这样的题目,大家首先想到的是暴力吧?
从\(x\)出发向上走到根,标记每个经过的节点。
从\(y\)出发向上走,经过的第一个有标记的节点就是"x到y路径上深度最小的节点"\((LCA)\)。
\(Code:\)
1 | int LCA(int x,int y) |
但是让我们算算复杂度... \(\Theta(N)\ \)TLE
为什么复杂度如此之高?明显是因为走得太慢了。
我们需要更好的算法。
怎么做呢?
睿智的先人想到了倍增树剖
先把树剖分成一条条的链
每次直接跳一整条链,不就快了吗?
于是,树链剖分(\(Tree-chain\ Partition\))诞生了。
预处理
先来说剖分:
剖分,是指依据某种运算,将几个节点分入同一条链,而将一颗树分成几条链的方法。
看不懂没关系反正它不重要
常见的剖分有三种: 1. 重链剖分 2. 实链剖分(Link-Cut Tree才用) 3. 长链剖分(几乎不用)
所以,我们讲的是重链剖分
重链剖分依据啥呢?依据的是儿子的子树大小,即\(x\)子树最大的儿子与\(x\)属于同一条重链。
首先定义几种变量: - \(dep_x\):\(x\)的深度 - \(fa_x\):\(x\)的父亲 - \(siz_x\):以\(x\)为根的子树的节点数 - \(son_x\):\(x\)的重儿子 - \(top_x\):\(x\)所在重链的顶端编号 - \(root\):整棵树的根 - \(son(x)\):\(x\)的儿子所构成的集合
所以我们先要dfs一遍把前4种值算出来。
\(Code:\)
(\(head,ver,next\)均为邻接表,不会的你还看什么树剖请先学会)
1 | void dfs1(ci&x){//ci -> const int,后文同 |
算完了前\(4\)种值,\(top\)该怎么算呢?
根据定义,一条重链上的节点的\(top\)值相同。
而在重链剖分中,\(x\)和\(son_x\)在一条重链上。
是不是发现了什么
于是我们得到了一条规律: \[ top_x= \begin{cases} &x &|x\neq son_{fa_x}\\ &top_{fa_x} &|x=son_{fa_x} \end{cases} \]
是不是很简单
所以我们就可以愉快的再dfs一遍计算啦
\(Code:\)
1 | void dfs2(ci&x){ |
预处理复杂度\(\Theta(N)\)
剖完后的树 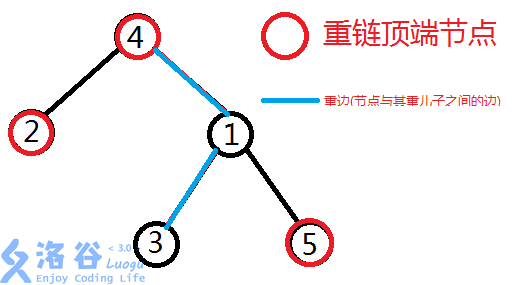
查找LCA
有人问,把链剖出来有对于查LCA什么用呢?
我答:还记得暴力为什么TLE吗?
走太慢啦!
所以,树链剖分的实际作用——加速!
但是,剖完后如何查找呢?
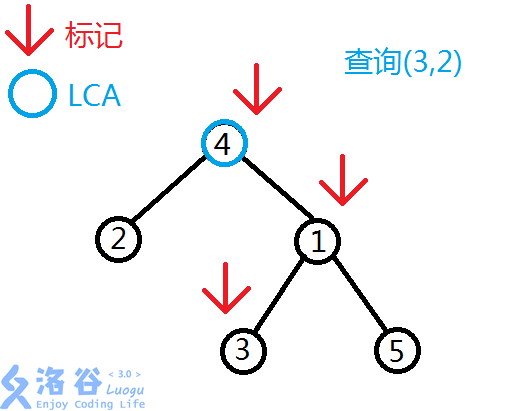
经过苦思冥想, 我们发现一条规律:
无论什么时候,只要两个节点不在一条重链上\((\)即\(top_x!=top_y)\),那么他们的\(LCA\)肯定不在深度大的那条重链上。
所以,我们可以这样: 1. 对于点对\((x,y)\),记\(fx=top_x,fy=top_y\). 2. 如果\(fx!=fy\),转第3步;否则转第4步. 3. 将\(fx,fy\)中\(dep[]\)值大的往上跳(设\(dep_{fx}>dep_{fy}\)),更新\(((x,y)->(fa_{fx},y))\),回到第2步. 4. 这时\((x,y)\)肯定在一条重链上\((top_x=top_y)\),而深度较小的那个就是\(LCA\).
\(Code:\)
1 | int LCA(int x,int y) |
那么这种加速跳法的效果怎么样呢?
可以证明单次操作的时间复杂度 \(\Theta(lgN)\)。
证明
我们需要\(3\)个定理:
- \(\forall y\in son(x)\ \&\ y\neq son_x\),都有\(siz_y\le \frac{siz_x}{2}\)
反证法,假设有 \(siz_y>\frac{siz_x}{2}\)且\(y\in son(x)\) 那么就有 \(y=son_x\),与定理矛盾 所以假设不成立,原命题成立
- \(\forall x\in son(root)\) ,从 \(root\) 到 \(x\) 的路径上存在不超过 \(lgN\) 条轻边
因为每经过一条轻边,到达的点的\(siz\)就会减半 所以最多减 \(lgN\) 次 \(siz_x\) 就变成 \(1\) 了(到达叶子节点)
- \(\forall x\in son(root)\) ,从 \(root\) 到 \(x\) 的路径上存在不超过 \(lgN\) 条重链
因为一条重链的两端必定是轻边 所以重链的数量比轻边少一条(重链通向 \(root\) 除外) 最坏情况下轻重链数量一样,为 \(lgN\)
如果每次我们跳过一条重链,这样的重链有 \(lgN\) 条
时间复杂度就为 \(\Theta(lgN)\) 啦
例题P3379
找\(LCA\)的板子题
这里是BFS实现版(不知道为什么更慢)
套线段树
又有睿智聪明的小盆友问了:
这个奇怪的东西怎么套线段树呢?
我们来再看一看树链剖分后轻重边的分配情况:
如果我们把链拼成一个序列,就像这样:
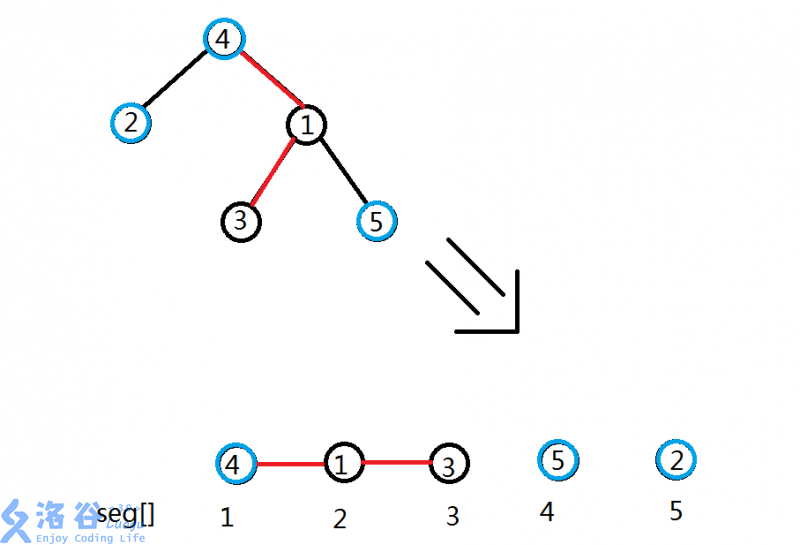
那么是不是可以用线段树维护呢?
不是也得是
如何确定每个节点在序列中的位置呢?
我们回到\(dfs2()\)中
很容易发现一个性质:
对于同一条重链上的节点,他们一定是被连续访问的!
所以我们可以直接在\(dfs2()\)中计算出每个节点在序列中的位置(其实就是重标号)
\(Code:\)
1 | void dfs2(int x) |
接下来的问题是:
如果要查询一条路径上的权值和/最大值,怎么办呢?
记\(x\)到\(y\)的路径权值和为\(sum(x,y)\)。
来看这张图: 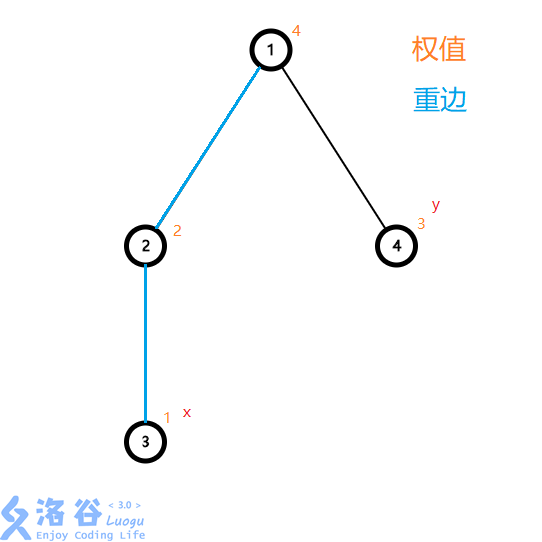
假设现在查询\(sum(3,4)\)
将上图树拆成序列,用线段树维护 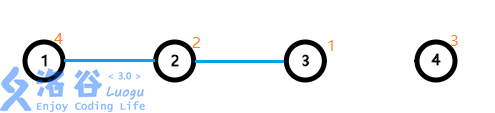
可以发现,如果\(top_x\neq top_y\),那么\(dep_{top}\)较大的那条链的全部节点都在答案中(即\(sum(x,top_x)\in sum(x,y)\) | {\(top_x\neq top_y\ \&\ dep_x>dep_y\)})
又因为我们的重链节点是连续储存的,在线段树中是一段区间
不用我说了吧
和之前一样,当计算完当前链的答案后,\(x\)跳到\(fa_{top_x}\)
最后\(top_x==top_y\)时,只用计算\(sum(x,y)\)这一段区间了。
整理一下:
设\(fx=top_x,fy=top_y\)。
若\(fx==fy\),执行第4步;否则,设\(dep_x>dep_y\),执行第三步。
计算\((x,top_x)\)对答案的贡献,\(x=fa_{top_x}\)。
设\(dep_x<dep_y\),计算\((x,y)\)对答案的贡献
\(Code:\)(以求和为例)
1 | int query_sum(int x,int y) |
同样的,我们可以推广到 求\(max\)/ 求\(min\) /修改 的操作
因为每次跳重链都要进行\(\Theta(lgN)\)的查询
所以时间复杂度\(\Theta(lg^2N)\)
例题P2590
认真看代码,不会很难
后话
看完之后这些题就可以愉快地WA\(AC\)啦
主要是线段树上的区间修改